

Should Artificial Intelligence be Used in Foreign Policy?


Allow me to begin with the BLUF (the “Bottom line up front,” as they say in the military): My view is that AI can be a powerful assistant for tasks for which we already have expertise. However, I am quite wary of AI’s use for tasks on which the user can’t personally validate the quality of the answer the machine produces.
I should caveat that there’s a lot of uncertainty and speculation here. The technology is evolving so rapidly, what’s true today might be wrong tomorrow. I know a lot of you have been thinking about this issue as well, and I’d love to hear your thoughts. Please shoot me an email or post in the comments.
Understanding AI Helps Know its Limitations
In order to understand AI’s limitations and strengths, it’s important to understand how it works. I want to focus first on large language models (LLMs) like ChatGPT, which have been so prominent in the news lately, and then I’ll briefly touch on other models of AI at the bottom.
To get an LLM up and running, its engineers design a fancy algorithm and then “train” it with a huge amount of written data. For example, Google’s LLM, called Gemini, is said to have been trained with roughly 800 billion books worth of information.
When the LLM is sent a query by a user, the algorithm pattern-matches your wording to words and sentences in its training data. The LLM does not try to understand the logic of the question — instead, it identifies similar-looking sentences in its database to produce an answer.
The LLM is designed to select the next words in a sentence statistically, according to patterns its algorithm identifies in its vast training data, not because it can understand meaning when words are strung together.
A simplistic example: If you ask the LLM “What is 5x2?” it will answer 10. But not because it can actually do the math. Instead, the model will search its database, find millions of old references to “5x2” and see that “10” is (almost) always the response. If someone hacked into the underlying training data and changed every instance of “5x2=10” to “5x2=horse,” that’s what the LLM would tell you.
It is essential to understand that large language models (LLMs) do not allow for fact-checking. One cannot investigate the source or citation from which the LLM algorithm extracted its information. Nor are they programmed to evaluate the quality of evidence it uses to support its claims. The user cannot trace where the generated text came from.
This is worrying because the AI will often be wrong. If the question being asked is novel, the LLM will do its best to assemble an answer that seems intelligent, but that doesn’t make it right. The algorithm can even manufacture a completely fake answer – programmers call these “hallucinations.”
Even if the query is not completely novel, the algorithm is only as good as its training data. This is called “data dependence.” LLMs are reliant on the quality of information they're trained on. The algorithm excels at assembling old knowledge in new ways, but it can't truly "think outside the box." If the underlying data is wrong – because of general misunderstanding, bias, or even purposeful manipulation – the LLM will echo that wrongness.
To summarize: an LLM cannot exercise judgment, logic, or analysis. It uses statistics to identify patterns between words. It is often wrong. Thus, we cannot blindly rely on an LLM’s output as a source of truth.
My instinct is that LLMs will never be able to solve this “truth” problem. Even if the LLM is trained using quality data – for instance, if it was trained only to read official State Department cables – these problems cannot be completely eliminated. An LLM will never understand its own answers.
What are AI’s biggest strengths?
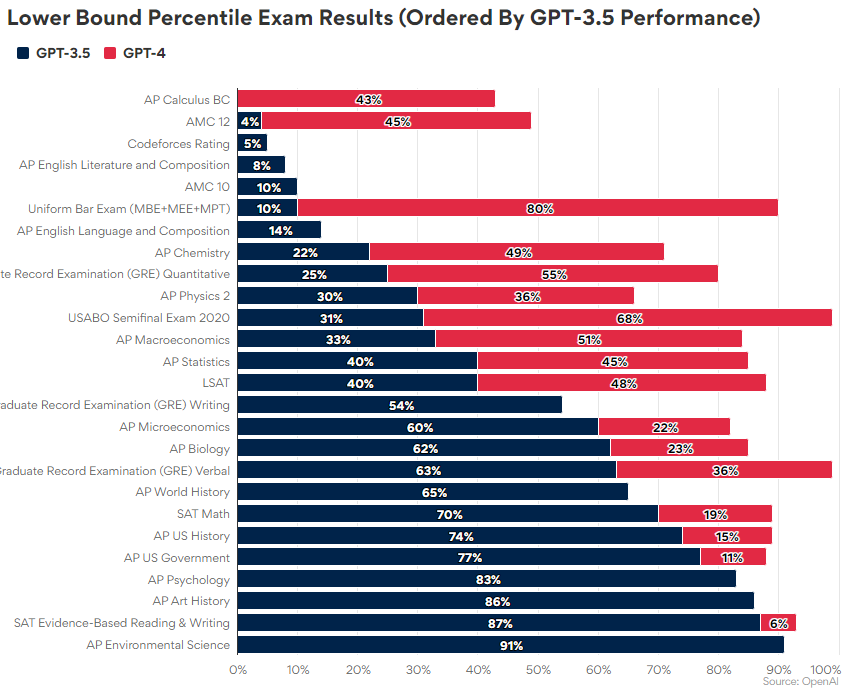
One of AI’s biggest strengths is as a knowledge management tool. AI (well, these LLMs, at least) can be enormously helpful in answering queries that are already well-represented within some corner of the digital world. Think of virtually any standardized test, and the LLM is probably performing far above the average test taker. The graph below from OpenAI, for instance, suggests that GPT-4 is likely to score in the 99th percentile on the GRE Verbal test, or the 90th percentile on an AP US History exam. (Note that the models perform poorly on other tests, however.)
LLMs can also be powerful allies for synthesis, pulling together threads of knowledge that haven’t been combined before. For example, I asked ChatGPT to rewrite the Star Spangled Banner as if it was written by Shakespeare. In its database, it will easily locate the national anthem, and has endless text by the Bard to draw from, and thus does an impressive job combining the two:
What direful sight, through yonder twilight beams, Across the ramparts, paints a gruesome scene? Is't but a meteor's fleeting, fiery gleams, Or rockets' blaze, where hostile battles preen? Nay, hold! It flutters yet! O say can we, Who through the perilous fight have bravely trod…
Another useful application of AI is to support brainstorming. One might ask ChatGPT to suggest five policy ideas to limit the spread of the conflict in Israel, for instance. You could even ask for each idea to be compared to a previous historical attempt.
The first rule of brainstorming is that “there are no bad ideas.” Yet at some point in the process, one needs to choose the best ideas. This is where the AI will fall short.
The Dangers of Naive AI Usage
AI is very good at giving plausible answers, but not always the best ones. We must not confuse the two.
AI is an amazing technology when we don’t care so much about finding the perfect answer. If we value speed over quality, AI is a powerful ally. But when the quality of our answers really matters, we need to invest in building real expertise.
That is why I believe one should already be an expert in the subject matter before using an LLM for any important task in which accuracy really matters.
Even simple summarization tasks worry me. Foreign policy, and especially diplomacy, relies on the nuance and context of words and ideas. Allowing AI into any space where interpretation matters seems like a bad idea. For example, if a foreign leader announces they are planning to “resist the president,” a good diplomat must discern if they mean military resistance or political resistance. If AI is relied upon to summarize the meeting, or something more complicated such as suggesting policy responses following, it will get us into trouble. Such nuances cannot be trusted to AI.
With this insight in mind, here are three kinds of tasks that AI is poorly suited for:
Fact-checking. The human still needs to have full expertise and agency over the results produced by the AI.
Judgment. The computer cannot consider ethics, political sensibilities, or values. Again, this is where humans need to continue to own the solution.
Causal Inference. Causal inference requires applying advanced reasoning to a body of evidence. Inference is necessary to understand past events (i.e. Why did Putin decide to invade Ukraine?) and is integral for any forward-looking policy: (i.e. How can the US best preserve Ukraine’s sovereignty?).
An additional concern I harbor is that AI will atrophy our existing processes and skills. I’m particularly worried about the degradation of our collective research and analytical skills, which lie at the heart of foreign policy. There’s no such thing as easy answers in international affairs. The hard labor of weighing conflicting evidence is what builds our deep understanding of the world. There are no shortcuts to expertise.
An organization like the US State Department must continue to invest in real expertise and avoid becoming reliant on “plausible” output from AI. Indeed, I think we are already suffering from an imbalance between precision and plausibility in US foreign policy, and AI will only exacerbate this problem.
Are Other Kinds of AI More Promising?
It is useful to make a distinction here between different types of AI. Each tool is designed to address a particular set of tasks. For instance, a search algorithm like Google can point one directly to original source material on the internet, but will not generate original text. In contrast, an LLM can generate original text, but cannot identify the original source material. Neither can validate when the information presented is “truthful.”
Other kinds of algorithms can program models to solve complicated problems or automate labor-intensive tasks. For instance, I often use Google Maps to calculate the fastest path between two points and steer me away from traffic jams. The algorithm is effective at this task because Google has endless, immediate data showing how other cars have successfully completed the trip. This makes their AI very effective at their task.
Another example. When I worked as a diplomat in Pakistan, we were not allowed to drive ourselves. We depended on a team of motorpool managers to match a limited number of drivers and vehicles to our meeting schedules. This is a task that an algorithm probably would have performed fast and efficiently.
A useful heuristic is that if you can describe exactly how to complete a task, you can probably get a computer to complete that task faster and more effectively than a human. If the underlying script is validated as “correct,” we can trust the results.
If there is no validated script—no preexisting correct answer—the AI might still be helpful, but a human user with enough expertise to distinguish truth from fiction ought to remain in the loop.
Conclusion
The problems that afflict AI also apply to human judgment. In foreign policy, our processes are already afflicted with flawed fact-checking, judgment, and causal inference processes. Given this, some argue that an imperfect computer program might be just as good as an imperfect human.
But we cannot simply accept today’s foreign policy in the United States as “good enough.” We must constantly strive to improve ourselves rather than simply replicate our weaknesses with a computer.
So, should AI be used in foreign policy? Yes, absolutely. But when should we use AI, and for what purposes? To answer this question, we’re going to need to use our brains.
I would like to hear your thoughts on the work of the State Department's Deputy Chief Data and AI Office. discussed in detail here - https://www.chinatalk.media/p/the-future-of-ai-diplomacy-can-the